Отзывы и обзоры хостинга





Избыточная нагрузка на диск на VPS: определение причин и устранение проблемы
Часто владельцы виртуальных и выделенных физических серверов обнаруживают, что несмотря на более чем достаточный объем свободной оперативной памяти (RAM) и процессорного времени (CPU) сайты работают медленно.
Если нет перегрузки сервера по процессору, оперативной памяти и сетевому порту, можно предположить, что причина - перегрузка дисковой подсистемы сервера (HDD) или ее недостаточная производительность.
Проблема актуальна для ситуаций, когда на сервере размещено большое количество VPS-контейнеров, а в качестве дисковой подсистемы используются жесткие диски типа SATA, независимые или объединенные в RAID-массив на программном уровне .
Менее подвержены проблеме VPS, размещаемые на мощных нодах с SAS-дисками в аппаратном массиве (подобная система может превышать традиционные SATA-диски по производительности в разы). Иногда проблема встречается и на независимых выделенных серверах, хотя и более редко, чем на VPS.
Рассмотрим порядок действий, который позволит определить источник проблемы и устранить ее:
1) Выясняем, действительно ли производительность дисковой подсистемы недостаточна (диск перегружен). На серверах с Linux нужно зайти на сервер по SSH, запустить мониторинг процессов top и посмотреть на показатель wa в строке Cpu(s):

На скриншоте выше указанный показатель отмечен красным прямоугольником. Wa обозначает процент времени простоя процессора в связи с ожиданием ввода-вывода. Простой будет тем выше, чем сильнее нагружена дисковая подсистема, так как на ожидание операций ввода-вывода потребуется больше времени. Если значение данного показателя стабильно выше 20%, то проблема действительно имеется, и требуется оптимизация работы дисковой подсистемы.
Пользователям VPS важно понимать, что высокие показатели wa в сочетании с низкой Load Average (LA) на контейнере сигнализируют о перегрузке дисковой подсистемы другим контейнером (контейнерами), и в данном случае решения проблемы следует ожидать в первую очередь от хостинг-провайдера.
На серверах с FreeBSD принцип определения данной проблемы похож – нужно запустить анализатор процессов ввода-вывода, выполнив команду iostat -x . В консоль будет выведена примерно следующая информация:
device r/s w/s kr/s kw/s wait svc_t %b aacd0 58.1 93.0 737.0 2606.7 0 78.2 33
Ключевые показатели:
wait - количество дисковых транзакций в очереди. Показатель, близкий к wa в Linux, но не в процентах, а в натуральных единицах. Чем он больше, тем серьезнее характер проблемы, так как если дисковая подсистема имеет достаточную производительность, число отложенных транзакций будет минимальным.
svc_t - среднее время транзакции в миллисекундах. Оптимально, когда данный показатель имеет низкие значения – на производительных и незанятых дисках операции ввода-вывода не будут выполняться долго.
2) Убедившись в наличии узкого места в работе дисковой подсистемы, нужно запустить анализатор процессов, который покажет, какие именно процессы/сервисы создают избыточную нагрузку на диск. Мы рекомендуем использовать анализатор atop. Эта замечательная утилита портирована и на FreeBSD c сохранением всего функционала, а также добавлением некоторых опций, специфических для этой операционной системы.
Запуск команды atop с опциями -Dd покажет процессы, нагружающие диск, и выполнит сортировку по столбцу DSK, показывающему нагрузку в процентах для каждого сервиса. Кроме того, критически нагруженные диски будут подсвечиваться красным цветом:
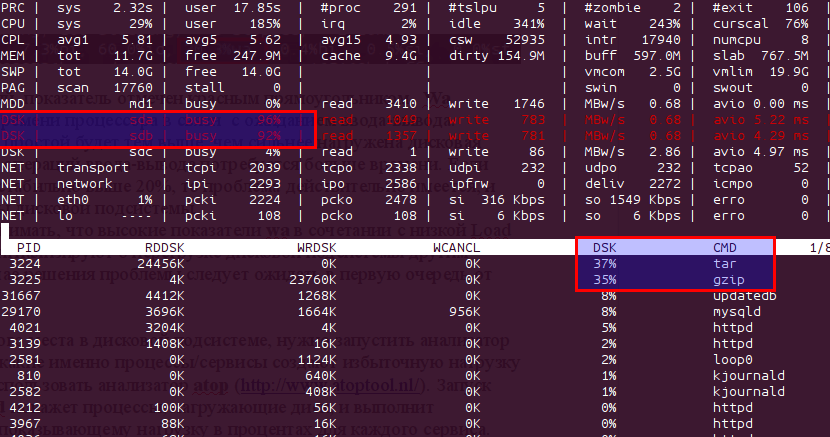
На скриншоте видно, что перегружены диски sda и sdb, а источником нагрузки являются процессы архивации и сжатия данных tar и gzip. Определив PID процесса, создающего нагрузку (на примере выше PID-ы проблемных процессов имеют значение 3224 и 3225), мы сможем получить более детальную информацию об этих процессах. К примеру, для получения информации о процессе tar с PID 3224, нужно выполнить комманду ps aux | grep 3224
3) Определив наличие проблемы и ее причины, перейдем к их устранению. Для этого нужно детально проанализировать процессы, создающие избыточную нагрузку на диск, и принять необходимые меры.
Например, если диск перегружается сервисом MySQL (что не редкость), можно провести анализ запросов с помощью утилиты mytop, и определить и устранить медленные и тяжелые запросы к базе данных. Можно также вынести временные таблицы в RAM (tmpfs), что даст хороший эффект. Можно настроить файловое кеширование для сайта, чтобы сократить число запросов к БД и так далее.
Если диск нагружается веб-сервером Apache, и большинство запросов идут к статическим файлам, то можно установить Nginx в качестве фронт-енда к Apache, настроить прокси-кеширование и опять же, вынести прокси-кеш в RAM (tmpfs), а не хранить его на диске. Если диск перегружается из-за логирования большого числа запросов к сервисам, можно отключить логирование, направив запись логов в /dev/null, а при необходимости - снова его включить.
Вопросы, дополнения и замечания, пожалуйста, оставляйте в комментариях.
Комментарии
Отправить комментарий